


对象数组
对象数组指的就是存储引用类型的数组。
对象数组的使用
/*
*对象数组(引用数组):该数组中存储的是引用类型因此我们叫它对象数组或者引用数组
* 引用数组中存储的是对象的地址值而不是对象
*/
public class Demo {
public static void main(String[] args) {
//1.定义一个Student类型的数组
//int[] arr = new int[3]
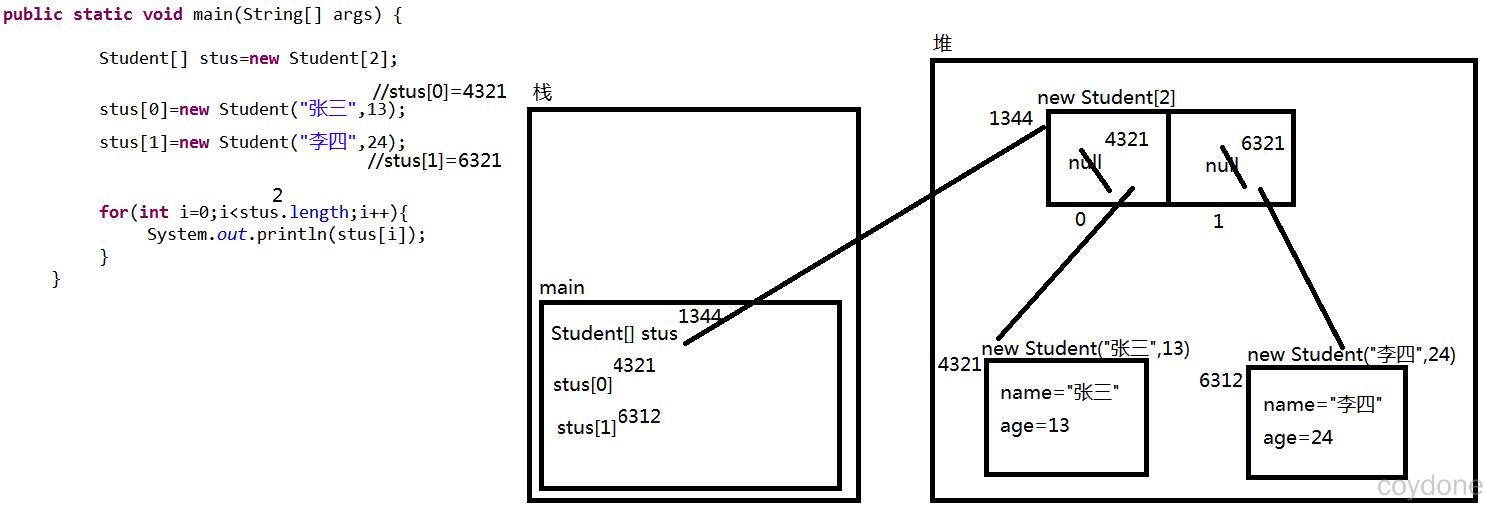
Student[] stus=new Student[2];
//2.给数组中的元素赋值
//arr[0]=3;
stus[0]=new Student("张三",13);
stus[1]=new Student("李四",24);
//3.遍历这个引用数组
/*
* for(int i=0;i<arr.length;i++){
* System.out.println(arr[i])
* }
*/
for(int i=0;i<stus.length;i++){
System.out.println(stus[i]);
}
}
}
内存图
List体系
List接口介绍
API中介绍:有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。与 set 不同,列表通常允许重复的元素。
List接口:
-
它是一个元素存取有序的集合。例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)。
-
它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
-
集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
-
List接口的常用子类有:ArrayList、LinkedList
ArrayList类
ArrayList是List接口的实现类,ArrayList底层是用数值实现的存储。特点:查询效率高,增删改效率低,线程不安全。
ArrayList实现原理
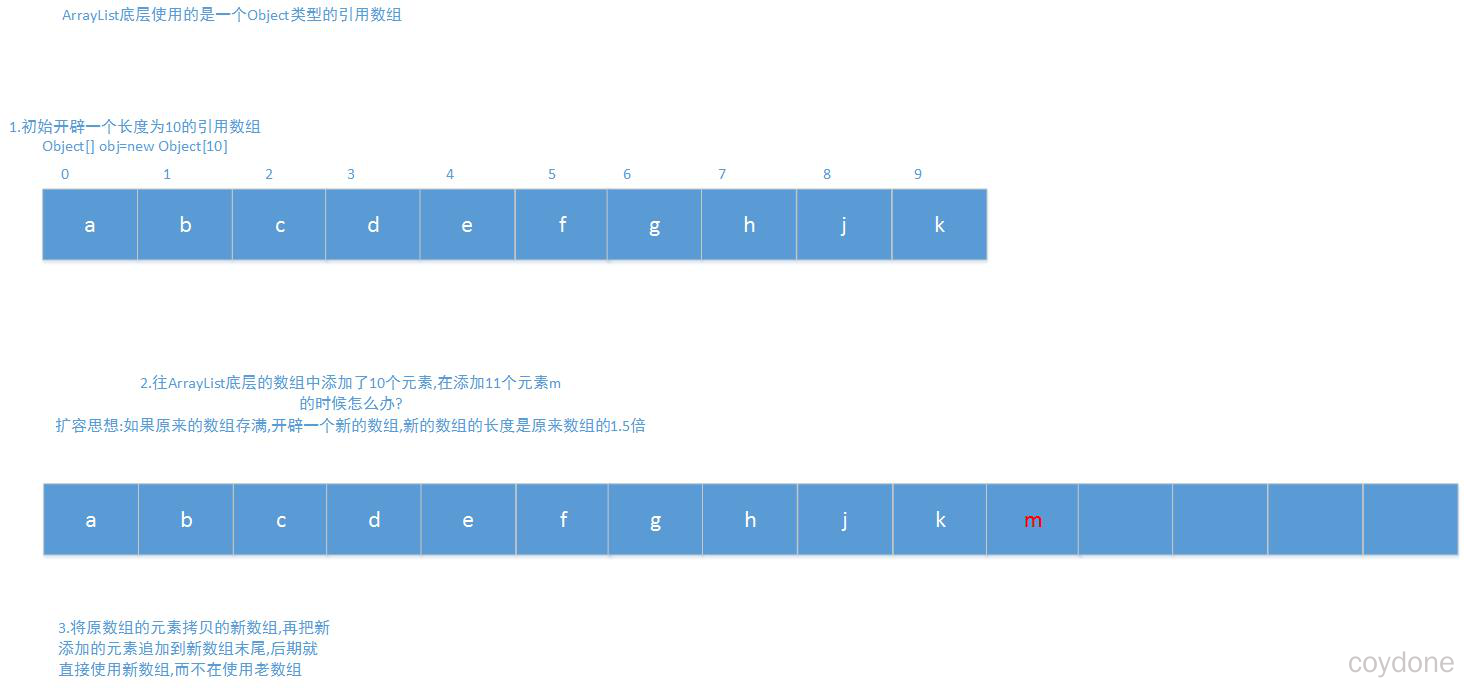
ArrayList集合特点:底层使用是一个引用数组(Object[])
扩容思想:创建一个ArrayList的时候,底层会生成一个空数组,当使用add()方法添加时,底层会开辟长度为10的数组,采用的是延迟初始化,调用add()方法会不断的往数组中添加元素当添加了10个元素。再添加第11个元素的时候,数组满了,无法存入,此时会新建一个长度为原来长度1.5倍的数组(10+10/2),接着会把原有元素拷贝到新数组中,再把第11个元素追加到末尾。
ArrayList中特有方法
增加元素方法
add(Object e):向集合末尾处,添加指定的元素
add(int index, Object e):向集合指定索引处,添加指定的元素,原有元素依次后移
删除元素删除
remove(Object e):将指定元素对象,从集合中删除,返回值为被删除的元素
remove(int index):将指定索引处的元素,从集合中删除,返回值为被删除的元素
替换元素方法
set(int index, Object e):将指定索引处的元素,替换成指定的元素,返回值为替换前的元素
查询元素方法
get(int index):获取指定索引处的元素,并返回该元素
方法演示:
import java.util.ArrayList;
public class Demo {
public static void main(String[] args) {
//list中可以存储任意数据类型,必须是对象
ArrayList list = new ArrayList();
list.add(12);//12是Integer一个对象,自动装箱
list.add("abc");
list.add("def");
list.add("abc");
System.out.println(list);//[12, abc, def, abc]
list.add(3,"zzz");
System.out.println(list);//[12, abc, def, zzz, abc]
System.out.println( list.get(1));//abc
list.set(3,"www");
System.out.println(list);//[12, abc, def, www, abc]
list.remove("abc");
System.out.println(list);//[12, def, www, abc]
}
}
ArrayList存储自定义对象
public class Person {
private int id;
private String name;
//省略构造方法、setter()、getter()、toString()
}
import java.util.ArrayList;
import java.util.Iterator;
public class PersonDemo {
public static void main(String[] args) {
ArrayList<Person> list = new ArrayList<Person>();
list.add(new Person(01,"张三"));
list.add(new Person(02,"李四"));
Iterator it = list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
//Person{id=1, name='张三'}
//Person{id=2, name='李四'}
}
}
ArrayList特点
查询元素较快:因为底层是数组,数组有索引。
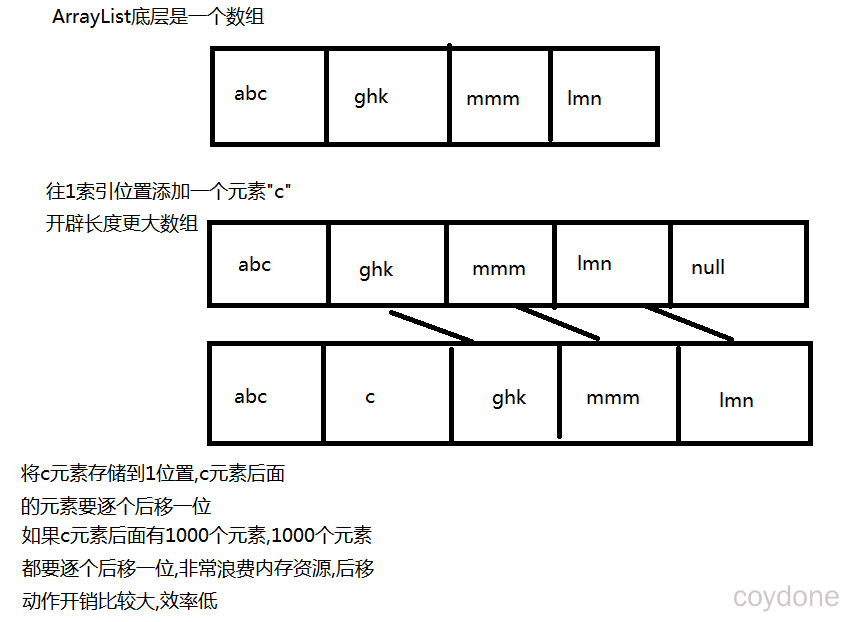
增删元素较慢:添加慢,因为每次添加都需要移动大量的元素,导致浪费内存资源,效率低。
添加慢的原因:
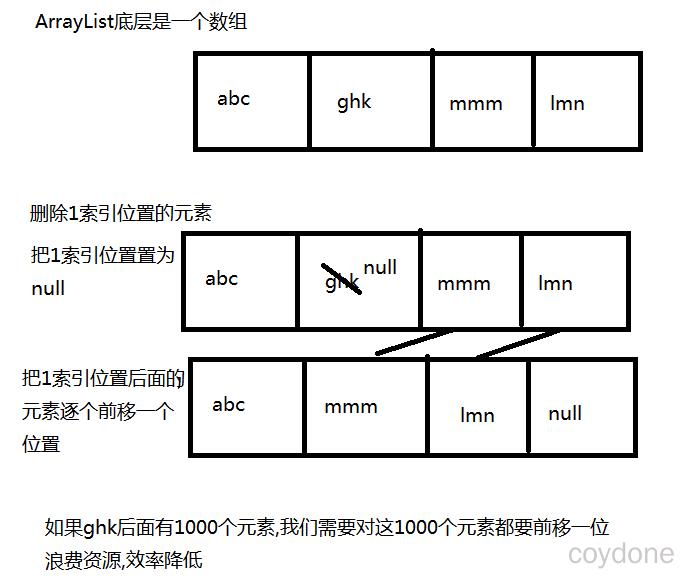
删除慢的原因:
Vector类
Vector底层是用数组实现的,相关的方法都加了同步检查,因此“线程安全,效率低”。比如,indexOf()方法就增加了synchronized同步标记。
Vector的使用与ArrayList是相同的,因为他们都实现了List接口,对List接口中的抽象方法做了具体实现。
Vector底层初始化数组采用的是立即初始化的方式,当创建Vector时底层就会创建长度为10的数组。Vector扩容是采用2倍的方式进行扩容。
Stack
Stack栈容器,是Vector的一个子类,它实现了一个标准的后进先出(LIFO:Last In First Out)的栈。
特点:后进先出。它通过5个操作方法对Vector进行扩展,允许将向量视为堆栈。
操作栈的方法:

public class Test {
public static void main(String[] args) {
//实例化栈容器
Stack<String> stack = new Stack<>();
//入栈
stack.push("aa");//返回值为该元素 aa
stack.push("bb");
stack.push("cc");
//查看栈顶的元素
System.out.println(stack.peek()); //cc
//查询对象在栈中的位置,从1开始计数,栈顶为1
System.out.println(stack.search("aa")); //3
//弹栈
System.out.println(stack.pop()); //cc
}
}
使用Stack判断元素对称性
//匹配符号的对称性
public static void symmetry() {
String str = "...{..{..[..()..]..}..}...";
Stack<String> stack = new Stack<>();
boolean flag = true; //假设是对称的
//拆分字符串获取字符
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (c == '{') {
stack.push("}");
}
if (c == '[') {
stack.push("]");
}
if (c == '(') {
stack.push(")");
}
//判断符号是否匹配
if (c == '}' || c == ']' || c == ')') {
if (stack.empty()) {
flag = false;
break;
}
String pop = stack.pop();
if (pop.charAt(0) != c) {
flag = false;
break;
}
}
}
if (!stack.empty()) {
flag = false;
}
System.out.println(flag);
}
LinkedList类
LinkedList底层用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。
双向链表也叫双链表,是链表的一种,它的每个数据节点中都有两个指针,分别指向前一个节点和后一个节点。所以,从双向链表中的任意一个节点开始,都可以很方便地找到所有节点。
双向链表
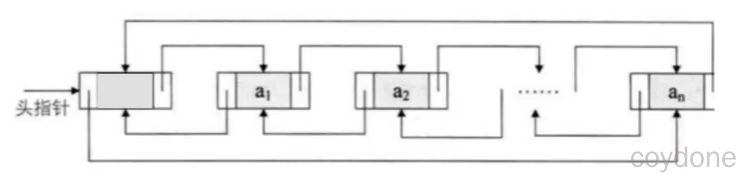
LinkedList实现思想
底层使用一个链表,第一个元素记录下一个元素的地址值最终形成一条链子。
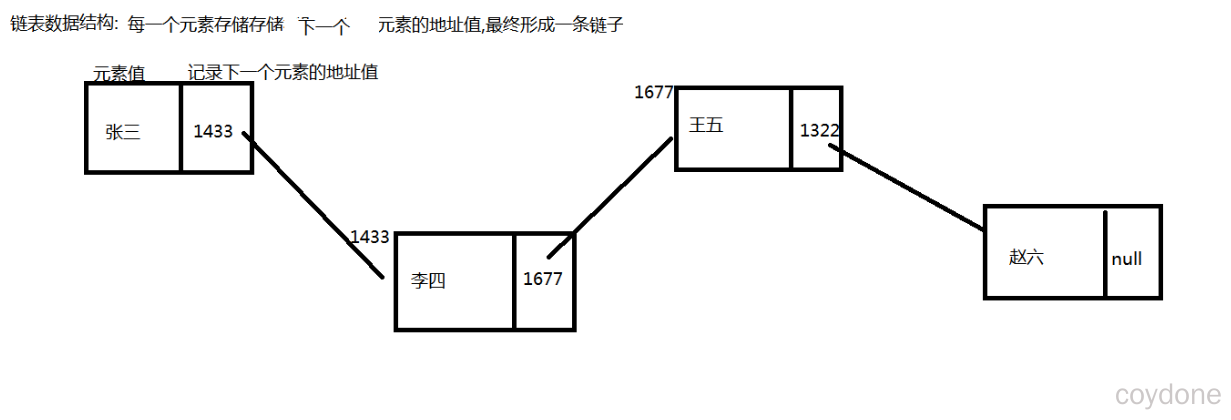
LinkedList特有方法

LinkedList特点
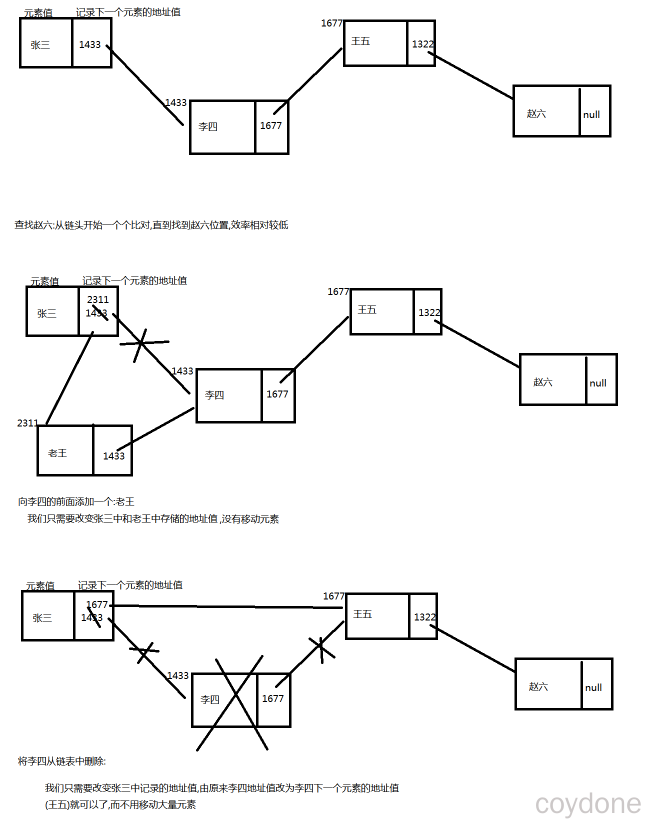
查询元素相对ArrayList较慢:因为链表都是从头开始查。
增删元素相对ArrayList较快:因为链表仅仅需要改变元素中记录的地址值,而不需要移动大量元素,节省内存开销提高效率。
栈和队列数据结构
-
栈:元素后进先出(先进后出),如手枪弹夹。
-
队列:元素先进先出(后进后出),如银行叫号。
LinkedList增删元素原理:
Set体系
学习Collection接口时,记得Collection中可以存放重复元素,也可以不存放重复元素,那么我们知道List中是可以存放重复元素的。那么不重复元素给哪里存放呢?那就是Set接口,它里面的集合,所存储的元素就是不重复的。
Set接口继承自Collection,Set接口中没有新增方法,方法和Collection保持完全一致。
Set接口介绍
Set特点:无序、不可重复。无序指Set中的元素没有索引,我们只能遍历查找;不可重复指不允许加入重复的元素。更确切地讲,新元素如果和Set中某个元素通过equals()方法对比为true,则只能保留一个。
Set常用的实现类有:HashSet、TreeSet等,我们一般使用HashSet。
HashSet类
HashSet是一个没有重复元素的集合,不保证元素的顺序,是线程不安全的。而且HashSet 允许有null元素。HashSet是采用哈希算法实现,底层实际是用HashMap实现的(HashSet本质就是一个简化版的HashMap,底层将值存在HashMap的key中),因此,查询效率和增删效率都比较高。
无序:在HashSet 中底层是使用HashMap存储元素的。HashMap底层使用的是数组与链表实现元素的存储。元素在数组中存放时,并不是有序存放的也不是随机存放的,而是对元素的哈希值进行运算决定元素在数组中的位置。
不重复:当两个元素的哈希值进行运算后得到相同的在数组中的位置时,会调用元素的equals()方法判断两个元素是否相同。如果元素相同则不会添加该元素,如果不相同则会使用单向链表保存该元素。
HashSet基本使用
HashSet依然具有集合通用的特点:利用add添加元素,使用迭代器遍历,使用增强for遍历。
方法列表:
add() remove() contains() clear() size()
-
Set无序,所有没有下标的获取方式。因此没有get(i)。
-
Set中不能查看一个元素
/*
* Set接口:没有索引,存储的元素唯一,存取顺序不一定一致
* HashSet:没有索引,保证元素唯一,存的顺序和取的顺序不一定一致
* 成员方法:
* Iterator<E> iterator()
*/
import java.util.HashSet;
import java.util.Iterator;
public class Demo {
public static void main(String[] args) {
HashSet<String> hs=new HashSet<String>();
hs.add("aa");
hs.add("bb");
hs.add("cc");
//1.获取迭代器对象
Iterator<String> it=hs.iterator();
//2.循环遍历
//迭代器
while(it.hasNext()){
String str=it.next();
System.out.println(str);
}
/*增强for
for(String str : hs){
System.out.println(str);
}
*/
}
}
import java.util.HashSet;
import java.util.Scanner;
import java.util.Set;
//Set集合过滤字符串
public class Demo {
//Scanner输入字符串去重
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("请输入字符串:");
String str = input.nextLine();
//1.String-->Char[]
char[] cs = str.toCharArray();
//2.Set集合
Set<Character> set = new HashSet<>();
//3.将每个字符放在Set中
for (int i = 0 ; i < cs.length ; i++){
set.add(cs[i]);//add()自带过滤重复
}
System.out.println(set);
}
}
add():判断对象是否重复,依赖contains()。
contains():底层依赖equals(),重写equals()就能在Set集合中解决对象重复的问题。
哈希算法
哈希算法,也称之为散列算法。Hash算法相对于普通查找更快。
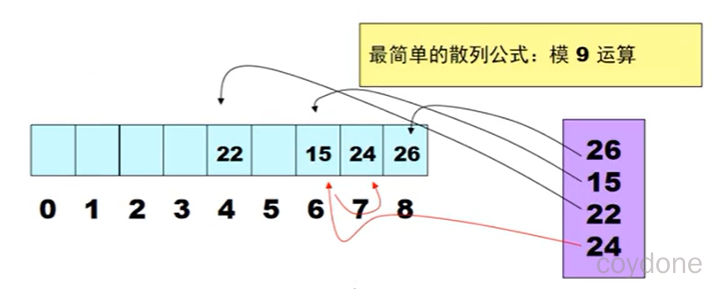
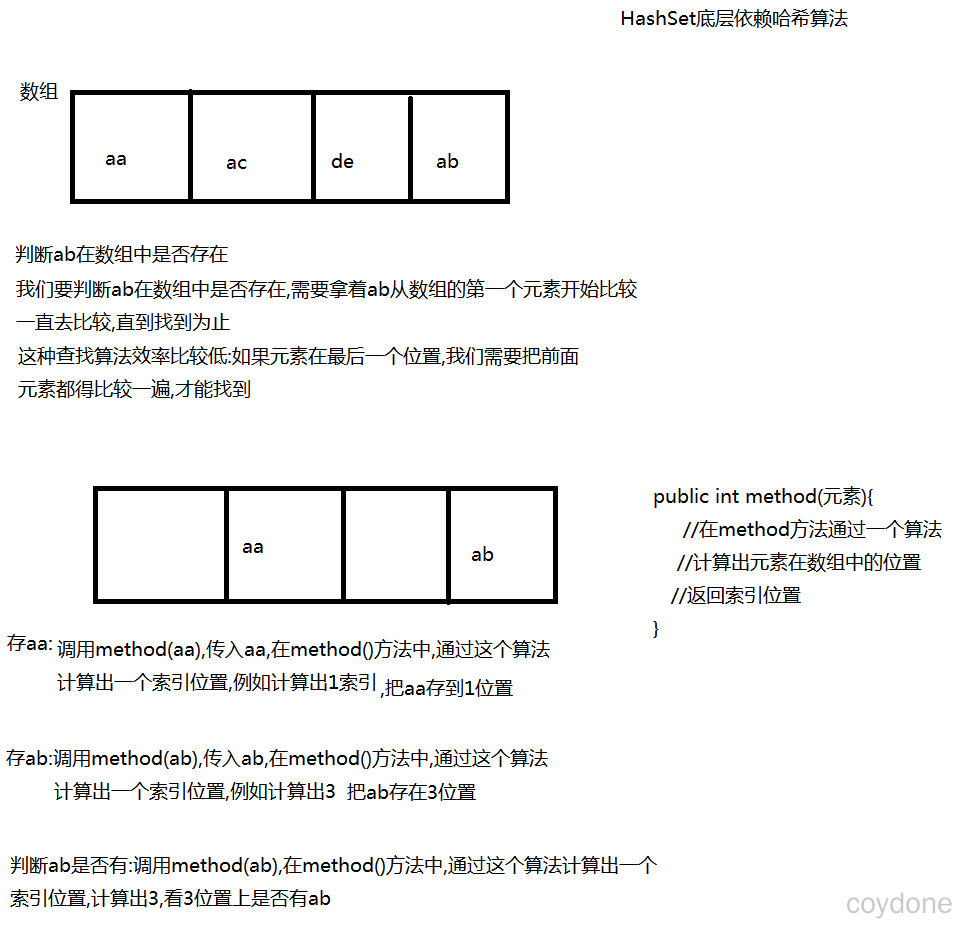
哈希算法保证唯一原理
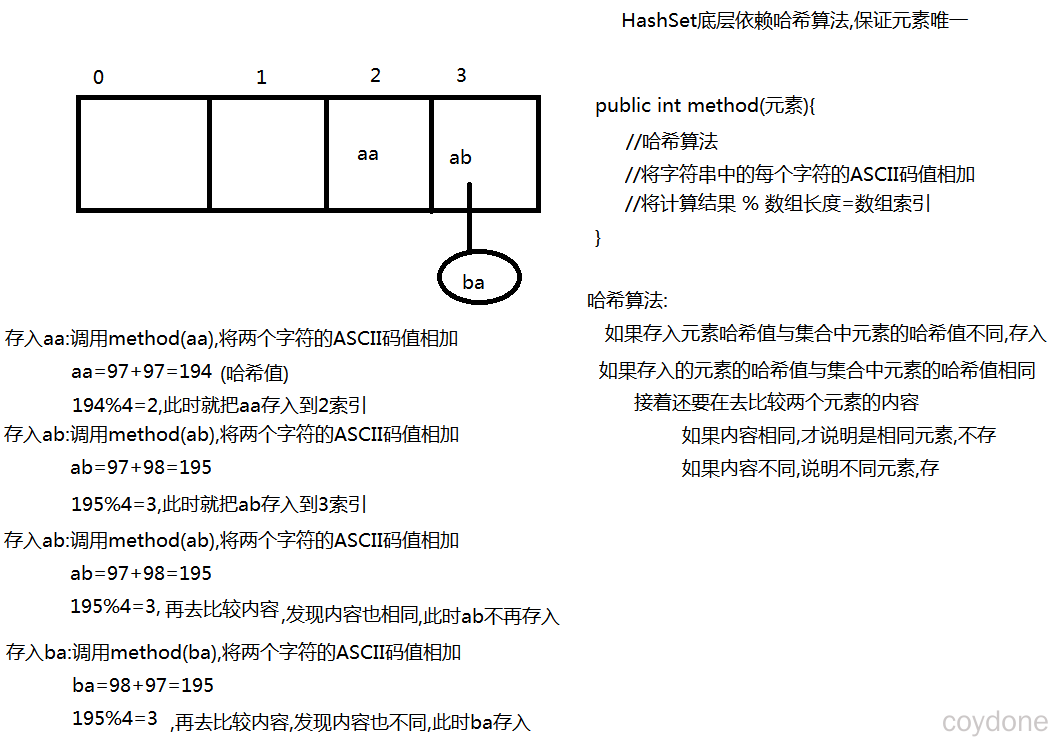
HashSet存入字符串保证唯一原理
存入HashSet的字符串依赖两个方法,一个是hashCode()方法,一个是equals()方法,注意这两个方法出自Object类,但是String都把这两个方法重写了,String的类的hashCode()方法不再像Object类的hashCode()方法返回内存地址值,而是根据一定的算法计算字符串中字符的ASCII码值,String类的equals()方法就是比较两个字符串的内容。
import java.util.HashSet;
/*
* HashSet唯一原理
* 先调用hashCode()方法比较元素的哈希值
* 如果添加的元素哈希值与集合中的元素的哈希值不同,直接存入
* 如果添加的元素哈希值与集合中的元素的哈希值相同
* 调用equals()方法比较两个元素的内容
* equals()返回true,说明两个元素内容相同,认为重复,不存
* equals()返回false,说明两个元素内容不同,存
* Object类中原始的hashCode()返回的就是内存地址值
*/
public class Demo {
public static void main(String[] args){
HashSet<String> hs=new HashSet<String>();
hs.add("ab");//当存入第一个ab时候直接存入
hs.add("ab");//当存入第二ab的时候,先调用hashCode()方法获取两个元素哈希值,比较发现相同
//在调用equals方法比较,"ab".euqlas("ab")//true,第二个ab就不存
hs.add("bc");//当存入bc的时候,先调用hashCode()方法获取两个元素哈希值
//比较发现不同,直接存入
System.out.println(hs);//[ab, bc]
System.out.println("ab".hashCode());//3105
System.out.println("bc".hashCode());//3137
}
}
HashSet存取自定义对象保证唯一原理
当我们存储自定义对象中出现同名同年龄的,利用HashSet不能去重。因为Person利用的是从Object类中继承的hashCode方法,获取的是元素的地址值比较,而每个Person都是新new的Person,地址值均不同。
public class Person /*extends Object*/ {
private String name;
private int age;
//省略构造方法、getter、setter方法
}
import java.util.HashSet;
/*
* 利用HashSet存储自定义对象
*/
public class PersonDemo {
public static void main(String[] args) {
//1.创建HashSet集合
HashSet<Person> hs=new HashSet<Person>();
//2.创建3个Person对象
/*Person p=new Person("张三",12);
*hs.add(p);
*/
hs.add(new Person("张三",12));//匿名对象
hs.add(new Person("张三",12));//调用hashCode()方法获取哈希值(内存地址值),去比较
//第二个Person对象的哈希值和第一个Person的哈希值不同
//第二个Person直接存入
hs.add(new Person("王五",16));
//3.遍历HashSet集合
for(Person p : hs){
System.out.println(p.getName()+" "+p.getAge());
}
//张三 12
//张三 12
//王五 16
}
}
我们尝试改写(重写)原有的hashCode()与equals()方法保证同名同年龄的人被过滤掉。
public class Person /*extends Object*/ {
private String name;
private int age;
//省略构造方法、getter、setter方法
/*我们在重写hashCode()一般用上这个类的所有属性来产生哈希值*/
/*@Override
public int hashCode() {
//return 10;
return name.hashCode() + age;
}*/
/*
*return 10,让所有元素都产生了相同哈希值,所有元素都得去调用
*equals()比较
* 对于new Person("张三", 12)还有new Person("王五", 16)
* 两者的姓名和年龄都不同,没必要再去调用equals比较
*/
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
/*
* euqual方法的重写与之前的相同
* 如果两个人的姓名和年龄均相同,认为是同一个人,返回true
* 如果两个人的姓名和年龄至少有一个不同返回false
*/
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
import java.util.HashSet;
public class PersonDemo {
public static void main(String[] args) {
// 1.创建HashSet集合
HashSet<Person> hs = new HashSet<Person>();
// 2.创建3个Person对象
Person p1=new Person("张三", 12);
Person p2=new Person("张三", 12);
Person p3=new Person("王五", 16);
hs.add(p1);//p1直接存入
hs.add(p2);//存入p2,需要调用hashCode()方法获取p1,p2的哈希值
//哈希值相同,需要再去比较equals(),返回true,认为相同元素,不存
hs.add(p3);//存入p3,需要调用hashCode()方法获取p3,p1的哈希值
//不同,直接将p3存入
System.out.println(p1.hashCode());//776222
System.out.println(p2.hashCode());// 776222
System.out.println(p3.hashCode());// 938522
// 3.遍历HashSet集合
for (Person p : hs) {
System.out.println(p.getName() + " " + p.getAge());
}
//王五 16
//张三 12
}
}
TreeSet类
TreeSet是一个可以对元素进行排序的容器。底层实际是用TreeMap实现的,内部维持了一个简化版的TreeMap,通过 key来存储Set的元素。TreeSet内部需要对存储的元素进行排序,因此,我们需要给定排序规则。
排序规则实现方式:通过元素自身实现比较规则、通过比较器指定比较规则。
通过元素自身实现比较规则
在元素自身实现比较规则时,需要实现Comparable接口中的compareTo()方法,该方法中用来定义比较规则。TreeSet 通过调用该方法来完成对元素的排序处理。
class User implements Comparable<User> {
private String name;
private Integer age;
//省略有参构造方法、getter()、setter()、toString()
//定义比较规则:正数 大,负数 小,0 相等
@Override
public int compareTo(User o) {
if (this.age > o.getAge()) {
return 1;
}
return -1;
}
}
public class Test {
public static void main(String[] args) {
Set<User> set = new TreeSet<>();
set.add(new User("张三",18));
set.add(new User("李四",15));
for (User user : set) {
System.out.println(user);
}
}
}
通过比较器实现比较规则
通过比较器定义比较规则时,我们需要单独创建一个比较器,比较器需要实现Comparator接口中的compare()方法来定义比较规则。在实例化Treeset时将比较器对象交给TreeSet来完成元素的排序处理。此时元素自身就不需要实现比较规则了。
class User {
private String name;
private Integer age;
//省略有参构造方法、getter()、setter()、toString()
}
class UserComparator implements Comparator<User> {
@Override
public int compare(User o1, User o2) {
if (o1.getAge() > o2.getAge()) {
return 1;
}
return -1;
}
}
public class Test {
public static void main(String[] args) {
Set<User> set = new TreeSet<>(new UserComparator()); //传入比较器
set.add(new User("张三",18));
set.add(new User("李四",15));
for (User user : set) {
System.out.println(user);
}
}
}
队列和栈
Queue、Deque
队列(Queue)是一种特殊的线性表,是一种先进先出(FIFO)的数据结构。它只允许在表的前端( front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
LinkedList是Queue接口的实现类
boolean add(E e):将指定的元素插入此队列(如果立即可行且不会违反容量限制),在成功时返回true,如果当前没有可用的空间,则抛出IllegalStateException。
E element():获取,但是不移除此队列的头。
boolean offer(E e):将指定的元素插入此队列(如果立即可行且不会违反容量限制),当使用有容量限制的队列时,此方法通常要优于add(E),后者可能无法插入元素,而只是抛出一个异常。
E peek():获取但不移除此队列的头;如果此队列为空,则返回null。
E poll():获取并移除此队列的头,如果此队列为空,则返回null。
E remove():获取并移除此队列的头。
Queue<String> queue = new LinkedList<>();
queue.add("aa");
queue.add("bb");
queue.add("cc");
System.out.println(queue.peek()); //aa
Deque:一个线性Collection,支持在两端插入和移除元素。此接口既支持有容量限制的双端队列,也支持没有固定大小限制的双端队列。接口定义在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。
Deque<String> deque = new LinkedList<>();
deque.add("aa");
deque.add("bb");
deque.add("cc");
System.out.println(deque.getFirst()); //aa
Stack
Stack:Stack类代表最后进先出(LIFO)堆栈的对象。它扩展了类别Vector与五个操作,允许一个向量被视为堆栈。设置在通常的push和pop操作,以及作为一种方法来peek在堆栈,以测试堆栈是否为empty的方法,以及向search在栈中的项目的方法在顶部项目和发现多远它是从顶部。
Stack<String> stack = new Stack<>();
//压栈
stack.push("aa");
stack.push("bb");
stack.push("cc");


评论区