


常见的数据库对象
| 对象 | 描述 |
|---|---|
| 表(TABLE) | 表是存储数据的逻辑单元,以行和列的形式存在,列就是字段,行就是记录 |
| 数据字典 | 就是系统表,存放数据库相关信息的表。系统表的数据通常由数据库系统维护,程序员通常不应该修改,只可查看 |
| 约束(CONSTRAINT) | 执行数据校验的规则,用于保证数据完整性的规则 |
| 视图(VIEW) | 一个或者多个数据表里的数据的逻辑显示,视图并不存储数据 |
| 索引(INDEX) | 用于提高查询性能,相当于书的目录 |
| 存储过程(PROCEDURE) | 用于完成一次完整的业务处理,没有返回值,但可通过传出参数将多个值传给调用环境 |
| 存储函数(FUNCTION) | 用于完成一次特定的计算,具有一个返回值 |
| 触发器(TRIGGER) | 相当于一个事件监听器,当数据库发生特定事件后,触发器被触发,完成相应的处理 |
视图
为什么使用视图
视图一方面可以帮我们使用表的一部分而不是所有的表,另一方面也可以针对不同的用户制定不同的查询视图。比如,针对一个公司的销售人员,我们只想给他看部分数据,而某些特殊的数据,比如采购的价格,则不会提供给他。再比如,人员薪酬是个敏感的字段,那么只给某个级别以上的人员开放,其他人的查询视图中则不提供这个字段。
视图的概念
视图:MySQL从5.0.1版本开始提供视图功能。一种虚拟存在的表,本身是不具有数据的,占用很少的内存空间,行和列的数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的,只保存了SQL逻辑,保存查询结果。
视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
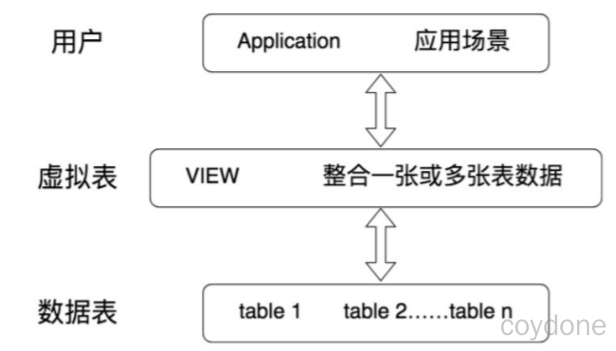
应用场景:多个地方用到同样的查询结果,该查询结果使用的SQL语句较复杂。
视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。
向视图提供数据内容的语句为 SELECT 语句,可以将视图理解为存储起来的 SELECT 语句在数据库中,视图不会保存数据,数据真正保存在数据表中。当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化;反之亦然。
视图,是向用户提供基表数据的另一种表现形式。通常情况下,小型项目的数据库可以不使用视图,但是在大型项目中,以及数据表比较复杂的情况下,视图的价值就凸显出来了,它可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。理解和使用起来都非常方便。
好处:重用SQL语句,简化复杂的SQL操作,不必知道它的查询细节,保护数据,提高安全性。
-
简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集。
-
安全:使用视图的用户只能访问它们被允许查询的结果集,对表的权限管理并不能限制到某个行某个列,但是通过视图就可以简单的实现。
-
数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,原表增加列对视图没有影响,原表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
/*
创建语法的关键字 是否实际占用物理空间 使用
视图 create view 只是保存了sql逻辑 增删改查,只是一般不能增删改
表 create table 保存了数据 增删改查
*/
#案例:查询姓张的学生名和专业名
SELECT stuname,majorname
FROM stuinfo s
INNER JOIN major m ON s.`majorid`= m.`id`
WHERE s.`stuname` LIKE '张%';
CREATE VIEW v1
AS
SELECT stuname,majorname
FROM stuinfo s
INNER JOIN major m ON s.`majorid`= m.`id`;
SELECT * FROM v1 WHERE stuname LIKE '张%';
创建视图
/*
语法:
create view 视图名
as 查询语句;
*/
#查询各部门的平均工资级别
#①创建视图查看每个部门的平均工资
CREATE VIEW myv2
AS
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id;
#②使用
SELECT myv2.`ag`,g.grade_level
FROM myv2
JOIN job_grades g
ON myv2.`ag` BETWEEN g.`lowest_sal` AND g.`highest_sal`;
查看视图
DESC myv3;
SHOW CREATE VIEW myv3;
# 查看视图的属性信息
# 查看视图信息(显示数据表的存储引擎、版本、数据行数和数据大小等)
SHOW TABLE STATUS LIKE '视图名称'\G
# 查看视图的详细定义信息
SHOW CREATE VIEW 视图名称;
更新视图
SELECT * FROM myv1;
#1.插入
INSERT INTO myv1 VALUES('张飞','zf@qq.com');
#2.修改
UPDATE myv1 SET last_name = '张无忌' WHERE last_name='张飞';
#3.删除
DELETE FROM myv1 WHERE last_name = '张无忌';
#具备以下特点的视图不允许更新
#①包含以下关键字的sql语句:分组函数、distinct、group by、having、union或者union all
#②常量视图
CREATE OR REPLACE VIEW myv2
AS
SELECT 'john' NAME;
#③Select中包含子查询
CREATE OR REPLACE VIEW myv3
AS
SELECT department_id,(SELECT MAX(salary) FROM employees) 最高工资
FROM departments;
#④join
CREATE OR REPLACE VIEW myv4
AS
SELECT last_name,department_name
FROM employees e
JOIN departments d
ON e.department_id = d.department_id;
#⑤from一个不能更新的视图
CREATE OR REPLACE VIEW myv5
AS
SELECT * FROM myv3;
#⑥where子句的子查询引用了from子句中的表
虽然可以更新视图数据,但总的来说,视图作为虚拟表,主要用于方便查询,不建议更新视图的数据。对视图数据的更改,都是通过对实际数据表里数据的操作来完成的。
修改视图
#方式一:
/*
create or replace view 视图名
as 查询语句;
*/
CREATE OR REPLACE VIEW myv3
AS
SELECT AVG(salary),job_id
FROM employees
GROUP BY job_id;
#方式二:
/*
语法:
alter view 视图名 as 查询语句;
*/
ALTER VIEW myv3
AS
SELECT * FROM employees;
删除视图
# 语法:drop view 视图名,视图名,...;
DROP VIEW emp_v1,emp_v2,myv3;
总结
视图优点
1、操作简单
将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简化了开发人员对数据库的操作。
2、减少数据冗余
视图跟实际数据表不一样,它存储的是查询语句。所以,在使用的时候,我们要通过定义视图的查询语句来获取结果集。而视图本身不存储数据,不占用数据存储的资源,减少了数据冗余。
3、数据安全
MySQL将用户对数据的 访问限制 在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。用户不必直接查询或操作数据表。这也可以理解为视图具有 隔离性 。视图相当于在用户和实际的数据表之间加了一层虚拟表。
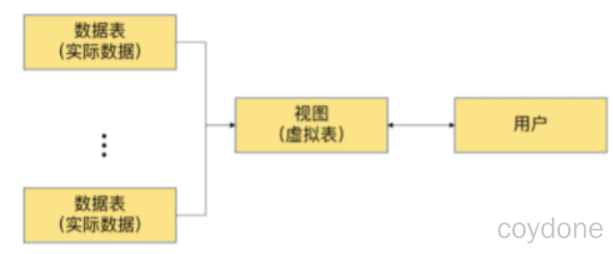
同时,MySQL可以根据权限将用户对数据的访问限制在某些视图上,用户不需要查询数据表,可以直接通过视图获取数据表中的信息。这在一定程度上保障了数据表中数据的安全性。
4、适应灵活多变的需求
当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较大,可以使用视图来减少改动的工作量。这种方式在实际工作中使用得比较多。
5、能够分解复杂的查询逻辑
数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。
视图缺点
如果我们在实际数据表的基础上创建了视图,那么,如果实际数据表的结构变更了,我们就需要及时对相关的视图进行相应的维护。特别是嵌套的视图(就是在视图的基础上创建视图),维护会变得比较复杂, 可读性不好 ,容易变成系统的潜在隐患。因为创建视图的 SQL 查询可能会对字段重命名,也可能包含复杂的逻辑,这些都会增加维护的成本。
实际项目中,如果视图过多,会导致数据库维护成本的问题。所以,在创建视图的时候,你要结合实际项目需求,综合考虑视图的优点和不足,这样才能正确使用视图,使系统整体达到最优。


评论区